做kernel需要准备的操作
文件系统
kernel题一般都会给出一个打包好的文件系统,因此需要掌握常用到的打包/解包命令
先把压缩包文件复制到虚拟机

解压
tar -xvf babydriver.tar解压,提取文件系统:
mv ./rootfs.cpio ./rootfs.cpio.gz
gunzip rootfs.cpio.gz
cpio -idmv < rootfs.cpio(有时解包出来很奇怪,可能是原始cpio文件其实是以gz格式压缩后的,先gunzip解压一遍)
题目文件
baby.ko就是有bug的程序(出题人编译的驱动),可以用IDA打开bzImage是打包的内核,用于启动虚拟机与寻找gadget.cpio文件系统start.sh启动脚本有时还会有
vmlinux文件,这是未打包的内核,一般含有符号信息,可以用于加载到gdb中方便调试(gdb vmlinux)没有
vmlinux的情况下,可以使用linux源码目录下的scripts/extract-vmlinux来解压bzImage得到vmlinux(extract-vmlinux bzImage > vmlinux),当然此时的vmlinux是不包含调试信息的。还有可能附件包中没有驱动程序
*.ko,此时可能需要我们自己到文件系统中把它提取出来,这里给出ext4,cpio两种文件系统的提取方法:ext4:将文件系统挂载到已有目录。(这里就直接偷图了,如果有问题麻烦联系我,速删)mkdir ./rootfssudo mount rootfs.img ./rootfs查看根目录的
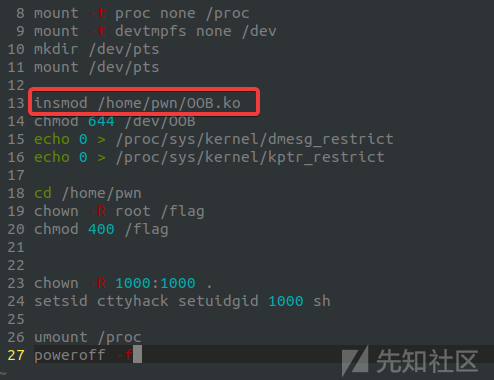
init或etc/init.d/rcS,这是系统的启动脚本
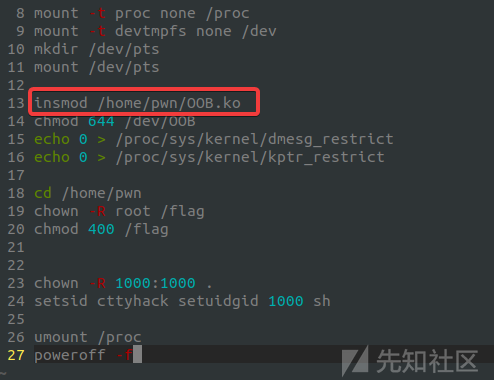
可以看到加载驱动的路径,这时可以把驱动拷出来卸载文件系统,`sudo umount rootfs`可以看到加载驱动的路径,这时可以把驱动拷出来
卸载文件系统,
sudo umount rootfs
带符号源码提取
使用脚本vmlinux-to-elf提取出带符号的源码
vmlinux-to-elf ./bzImage ./vmlinux开始调试的时候需要做的准备
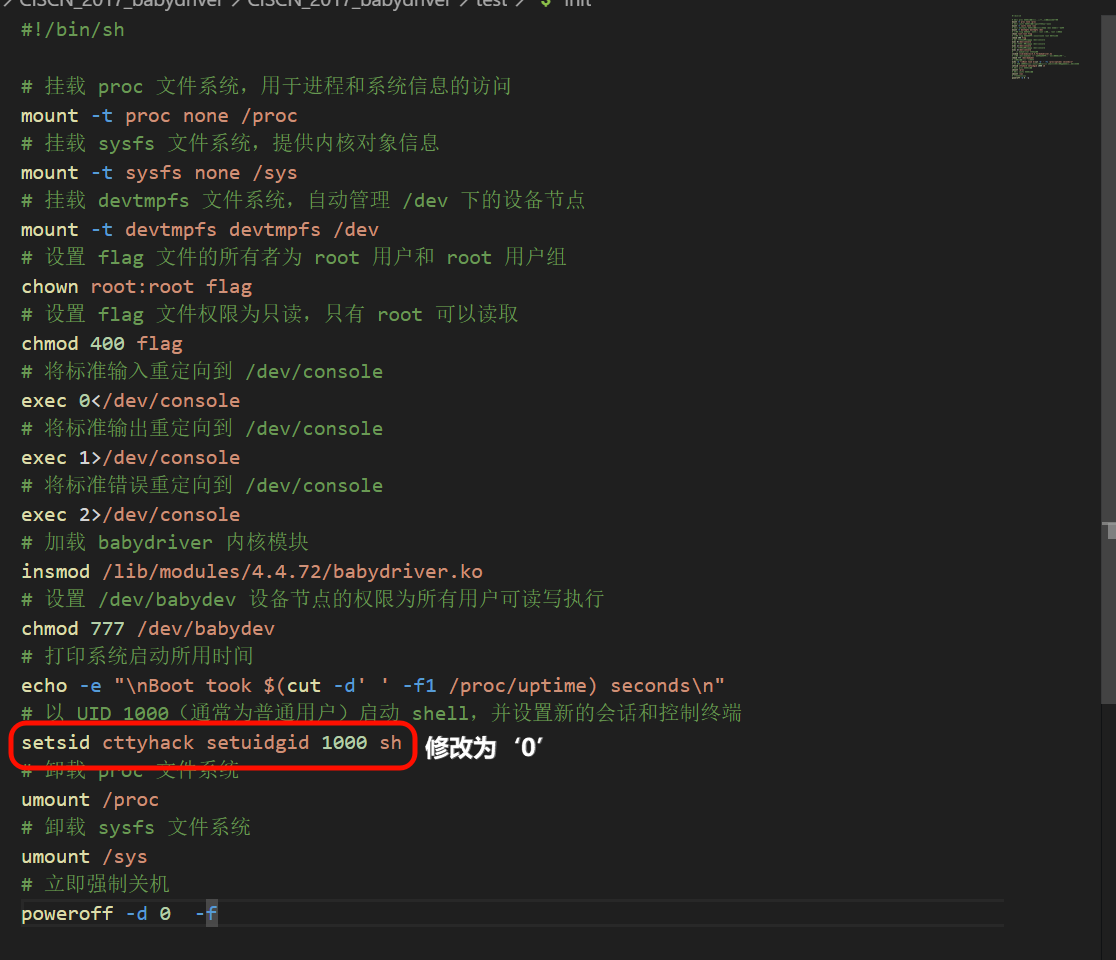
更改init使其方便以root运行:
查看镜像信息,准备下载相对于的linux的内核(可选):
strings bzImage |grep gcc
file bzImage
编辑start.sh来启动内核:
#!/bin/sh
qemu-system-x86_64 \
-m 64M \
-nographic \
-kernel ./bzImage \
-initrd ./rootfs.cpio \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 kaslr" \
-smp cores=2,threads=1 \
-cpu kvm64
如果想关闭内核地址随机化的话如下改start.sh
#!/bin/sh
qemu-system-x86_64 \
-m 64M \
-nographic \
-kernel ./bzImage \
-initrd ./rootfs.cpio \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 nokaslr" \
-smp cores=2,threads=1 \
-cpu kvm64
在qemu中找到babydriver.ko代码段的起始地址
运行下面命令就可以查看.text的基地址
cat /sys/module/babydriver/sections/.text
或者:
cat proc/modules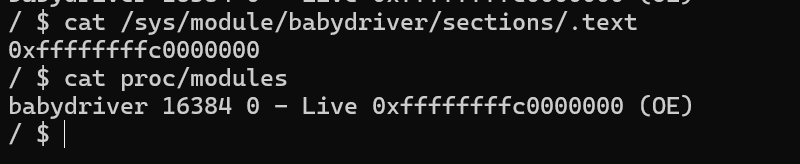
开始调试:
启动gdb语言:
gdb -q -ex "target remote localhost:1234"启动gdb过后导入符号表
add**-**symbol**-**file .**/**lib**/**modules**/**4.4.72**/**babydriver.ko 0xffffffffc0000000然后在boot.sh中添加以下参
-gdb tcp:1234需要使用的脚本
提取文件系统的脚本:
查看保护的脚本:
打包脚本pack.sh
#!/bin/bash
gcc \
./exp.c \
-o exp \
-masm=intel \
--static \
-g
chmod 777 ./exp
find . | cpio -o --format=newc > ./rootfs.cpio
chmod 777 ./rootfs.cpio远程脚本
为了减小远程exp的体积,使用musl进行静态编译()
from pwn import *
from pwn_std import *
p=getProcess("123",13,'./minho')
context(os='linux', arch='amd64', log_level='debug')
def send_cmd(cmd):
sla('$ ', cmd)
def upload():
lg = log.progress('Upload')
with open('exp', 'rb') as f:
data = f.read()
encoded = base64.b64encode(data)
encoded = str(encoded)[2:-1]
for i in range(0, len(encoded), 300):
lg.status('%d / %d' % (i, len(encoded)))
send_cmd('echo -n "%s" >> benc' % (encoded[i:i+300]))
send_cmd('cat benc | base64 -d > bout')
send_cmd('chmod +x bout')
lg.success()
os.system('musl-gcc -w -s -static -o3 exp.c -o exp')
upload()
ita()